Simulating genetic drift
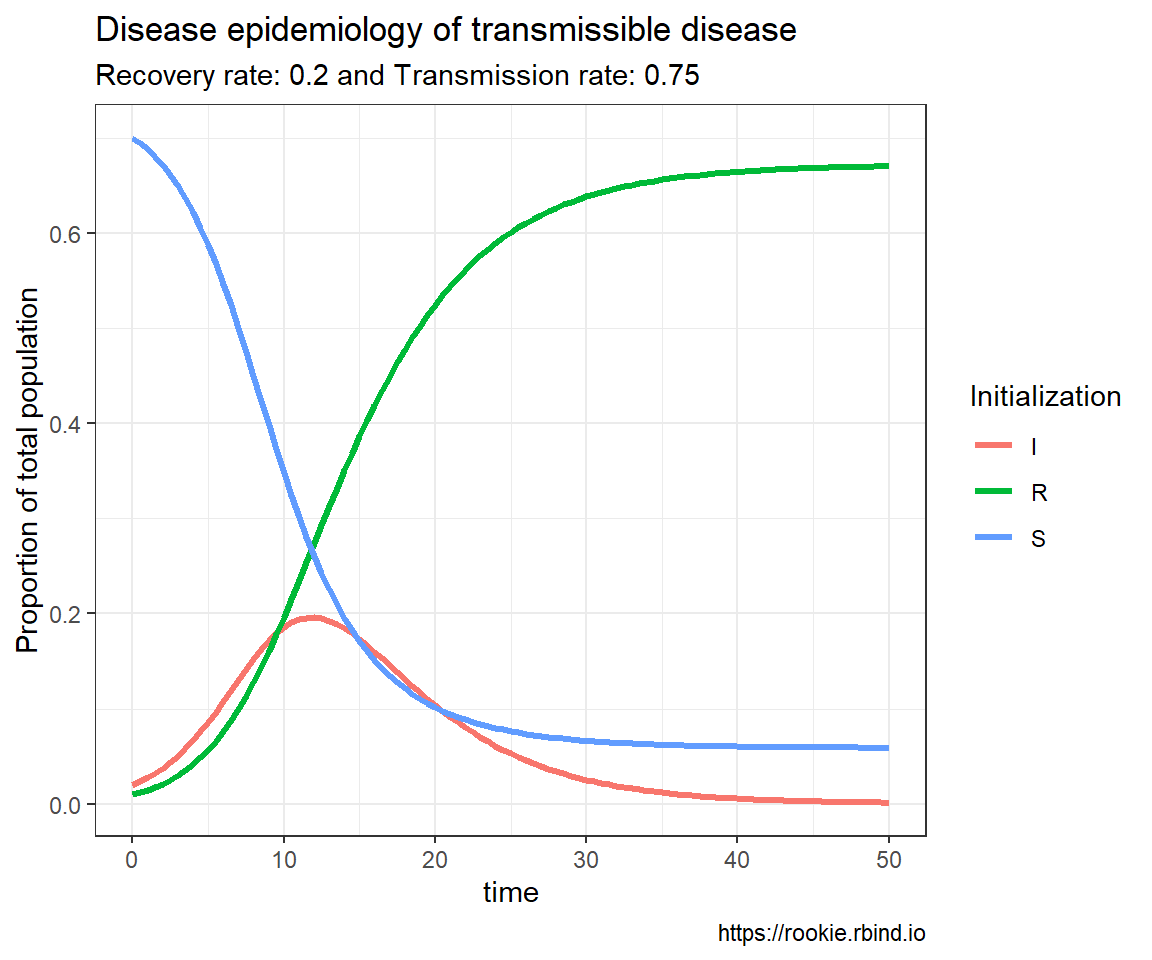
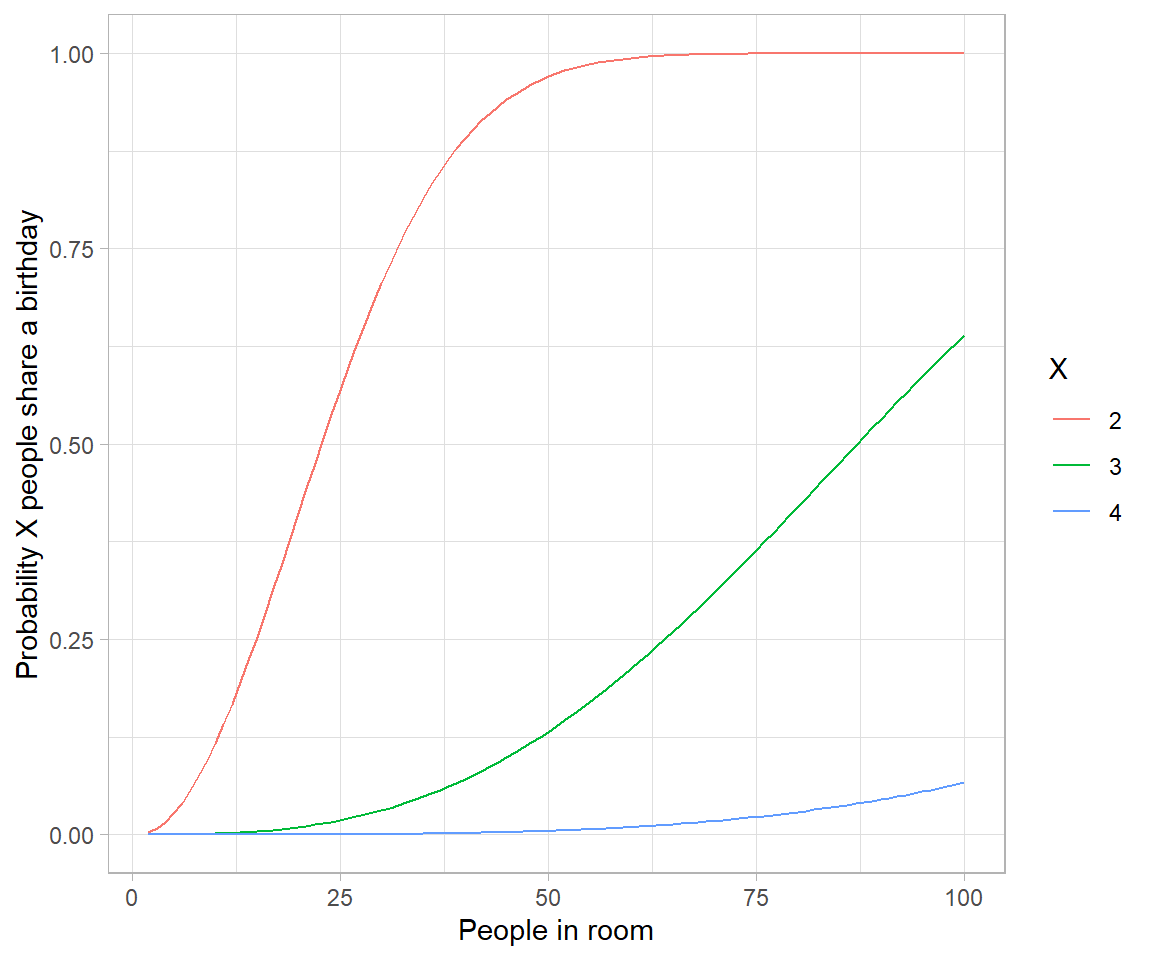
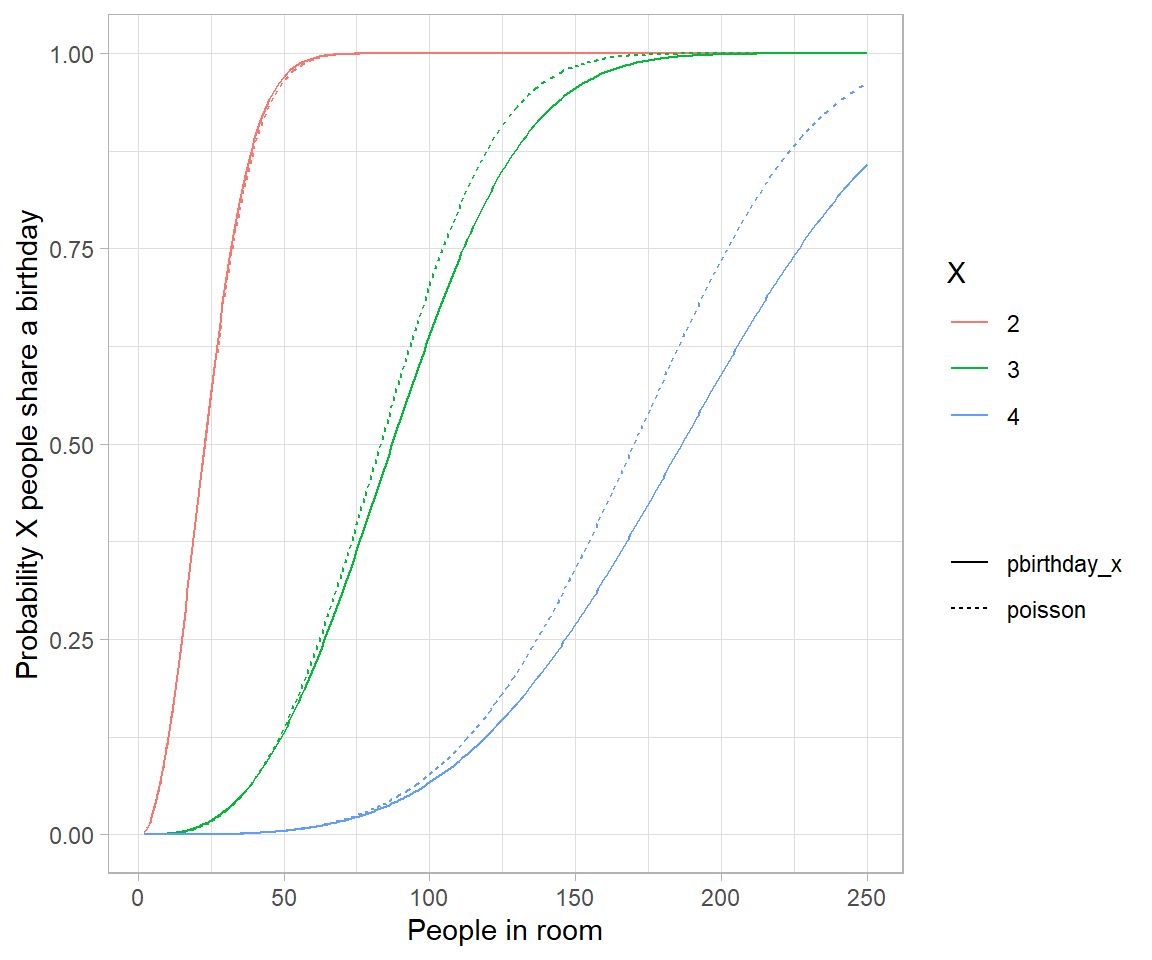
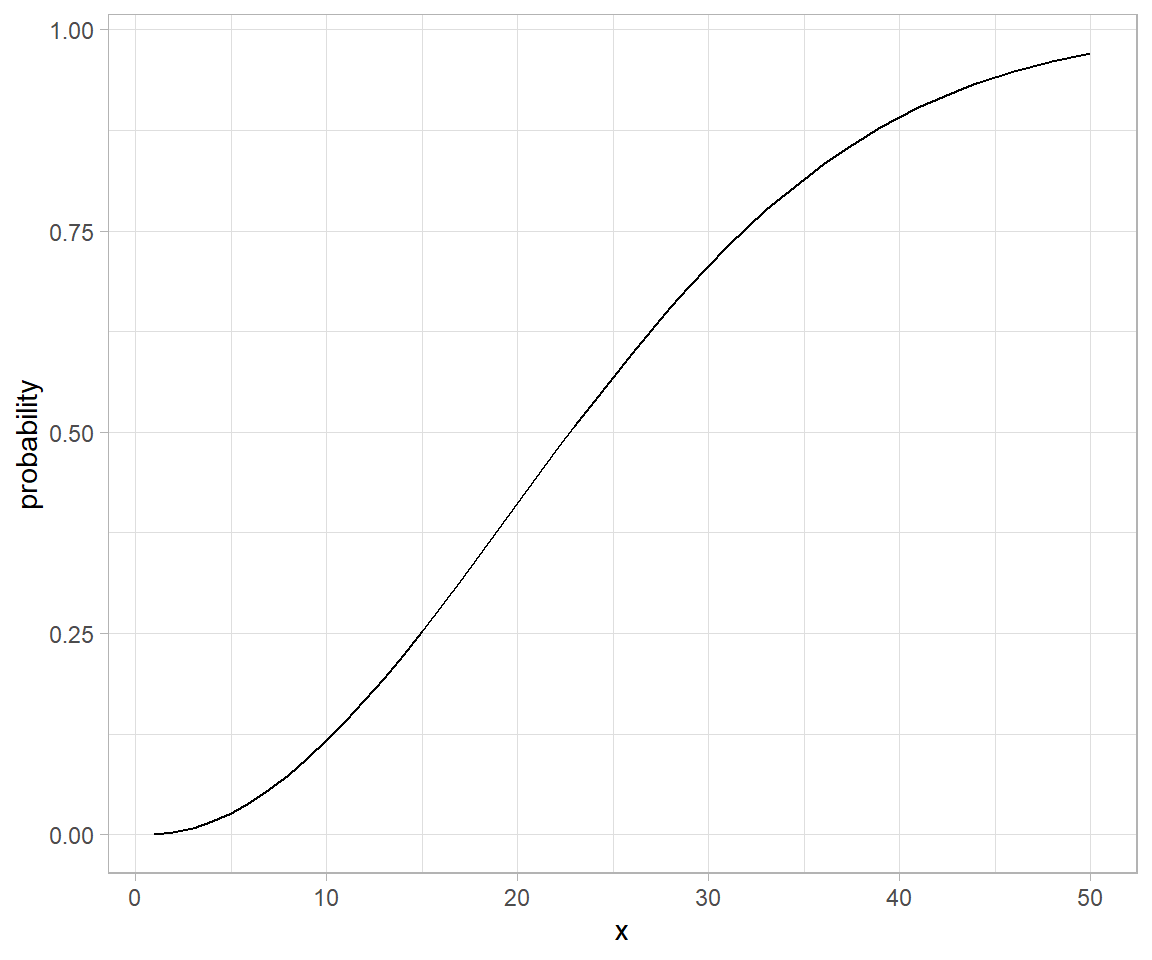
Genetic drift is the result of bernouli process on survival of individuals (given some probability for each of them) of a population over a number of independent trials (Generation).
Apparently there are two techniques of seeing such process – one individual level, other the population level. Both solutions are illustrated below. Let us suppose population of N individuals remains fixed from generation to generation, likewise, Fitness probability of “A” allele ($p(A)$) and “a” allele ($p(a)$) both starts off equal. Now we can generate incremental population survival probability for each individual for given population size: